老规矩,先解释一下标题,我承认有点标题党,其实就是为了抓人眼球,希望通过这种标题吸引你点进来看看。我有自信这是一篇好文章。我曾经写过一篇很有名的博客:《为什么C语言不会过时》 很多的网络媒体都进行了转载。我相信这篇博客的质量应该比《为什么C语言不会过时》还好。因为它会颠覆你对C++面向对象编程的传统的认知。
再详细解释一下什么是非耍流氓。其实C++面向对象编程的问题,很多大牛都讨论过,但是因为人家是大牛,所以文字描述居多,很少给出代码。人家毕竟是阅近天下**, 心中早已无码。我个人认为讨论编程的问题,如果你不给出代码就是在耍流氓。 而一些C++初学者,倒是愿意给出一大堆关于什么dog继承animal的类似的源代码,但是这样讨论面向对象编程有些肤浅,片面,甚至是把人带向了错误的方向。所以我这篇文章首先要基于源代码的方式讨论面向对象,而且介绍现代方式的面向对象编程,你会惊讶的发现,无论是从理念上,还是实现方式上,它都和传统意义的面向对象编程截然不同。
我刚开始接触C++的面向对象的时候,首先接触的例子就是duck是animal, student是一个people等等那一套。这种例子铺天盖地,充斥于各种C++的各种初级书本中。我相信大部分人和我都有一样的记忆。当时感觉这个面向貌似没什么难的。但是当自己写程序的时候,大部分时间都根本没怎么使用到继承。这个是第一个层次。
Class Animal{
Virtual Speak() = 0;
}
Class Duck: Animal{
Virtual Speak(){cout<<"quack"<<endl;
}慢慢地开始接触设计模式,这个就有点难度了。这里没有什么鸭子,学生之类的东西了。基本上都是一些很抽象的东西。比如说,策略是一个基类,命令是一个基类等等。当时看的云山雾罩,不得所以。只是机械的记住几个名字,几个类关系图而已。
再慢慢地,开始意识到一些本质的东西。继承是面向对象编程的核心实现方式,其思想本质是把变化的东西封装到子类中,而客户只针对一个基类的指针来调用:
Class Base{
Virtual Do{}= 0
};
Class Implement1: Base{
Do(){do it in this way};
}
Class Implement2: Base{
Do(){do it in thatway};
}
//Client code
Base* Ibase;
Ibase->do(); //如果你仔细研究设计模式,尤其是建造模式和行为模式,你会发现它们都符合这个基本的想法。例如工厂方法模式,我们把Do 函数换成Factorymethod方法就OK了,换句话说,我们把对象生成方法的变化下推到子类中,使得这种变化不会影响到客户的代码。再举了例子,策略模式,你把Do函数换成AlgorithmInterface()就可以了。我们把算法的变化封装到不同的子类中。当运行的时候调用不同的子类,客户端的代码也不受影响。顺便说一句,这种思想后面还有两个非常凡尔塞的原则。一个是里氏替换原则:如果S是T的子类型,则类型T的对象可以用类型S的对象替换(即类型T的对象可以用子类型S的任何对象替换(即向上转换))而不更改程序的任何期望属性(正确性,任务执行等)。其实就是我们能用Implement2替换掉IBase, 客户的程序不受影响。另外一个就是反向依赖原则:高层模块不应依赖低层模块,低层模块也不应依赖高层模块,两个都应该依赖抽象层。抽象不应该依赖细节,细节应该依赖抽象。 这个其实更简单, 换成人话就是一旦Do()这个玩意定下来,客户就去调用它,子类就去实现它。换句话说,客户不依赖于子类了,而是客户和子类都依赖于Do()这个玩意。这里很多人把Do()这个玩意也叫做接口,抽象,基类,契约等等。 看明白了吗?其实这两个原则其实说的都是一回事。
如果上面我说的你都明白,那么我恭喜你。你对传统意义的面向对象编程已经基本了解了,而且23个设计模式对你来说就不那么难懂了。
在传统的面向对象编程中,你会发现另外的两个问题,1) 什么应该是基类?2)如果基类需要变化怎么办? 而恰巧正是这两点,直接击中了传统面向对象编程的痛点。让我们一个一个说。 首先什么应该是基类?关于这个问题,C++面向对象里面有一个经典的案例,那就是:椭圆应不应该是圆的基类。我这里只是简单的介绍一下,详细的讨论可以参考后面的参考文献1。 长话短说,欧几里得认为圆形就是椭圆,但是C++里面你却不能这么用,这是因为椭圆有两个圆心,但是圆却只有一个圆心。 没有办法直接使用继承。请看源代码;如果使用了继承,你会发现圆这个类有三个圆心。而且setLongRadius在圆形里面也没什么实际的意义。这明显违背了里氏替换原则。
Class ellipse{
setLongRadius(float);
setShortRadius(float);
pair<float, float> center1;
pair<float, float> center2;
}
Class circle{
setRadius(float);
pair<float, float> center;
}问题出在哪里,到底是欧几里得错了? 还是Bjarne Stroustrup(C++之父)错了?大部分人的第一反应都是一定是我错了。然后针对这个问题,层出不穷的解决方案就出来了。但是无非就三种方法,让基类变弱,让子类变强。或者再建造一个更抽象的shape基类,然后让ellipse和circle都继承于它。但是无论是哪种方法,都相当的别扭和不自然。
如果如何在开始的时候设计类继承体系已经很成问题了,那么未来的变化更是大麻烦。 这里有另外一个例子。比如我们现在设计了一个面向对象的继承体系如下图:
Class Animal{
walk();
speak();
}现在People和Dog继承于它。 貌似非常地完美,没有任何问题。但是两个月以后,我们需要新加入一个类鲨鱼。问题就来了。鱼能继承于Animal吗?不能,因为调用Shark.walk()的方法没有办法解释。但是鱼明明就是一种Animal吗?没关系,面向对象是不会错的,C++语言也是没错的,只是我分类的方法不对。我应该再加入一个哺乳动物类,鱼类,然后把swim这个行为放到鱼这个类中。看着不错,虽然改变类体系这种事情会对现有的系统带来巨大的冲击和影响(几乎所有过去的代码需要改写和重新编译。)但是你相信现在的分类是完美的。但是两个月以后,鲸鱼来了。没关系,我们可以使用双继承去解决这个问题。(一旦使用了双继承,基本上就是代表你的设计需要一个补丁了。)鲸鱼同时继承哺乳动物类和鱼类,也算暂时过关了。但是两个月以后,鸭子来了。这个时候,我估计你快疯了。这个能walk, speak 和swim的东西到底应该放到哪里呢?真没想到,你会被一个鸭子伤害到。 其实你不是个例。 Linux之父炮轰过C++,指出任何现在看起来伟大,光明正确的类设计,两年以后都会有各种问题,那个时候修复起来成本很大,因为整个的系统实现都是基于现有的类设计架构,非常难于修改。同时继承关系是一种很强的耦合关系,这种强耦合使得整个程序变成了一大坨,牵一发而动全身。通过我们上面这个类似玩具的例子,我希望你能对这句话有所体会。
传统面向对象编程(我是指那种上来就去设计复杂的类的分类和继承体系)的问题在于把人类日常科学的分类方法照搬到编程领域,这是不对的。再详细点说,is-a关系并不能完美地适用于编程领域,is-substituable(可替代关系)更适合。在Python语言中,这种思想得到了贯彻和体现。Python语言中有著名的(duck type)鸭子类型。只要你叫起来象鸭子,走路像鸭子,那么你就可以替代鸭子。 至于你本身是什么,我不care。
我们再论is-substituable(可替代关系),现代面向对象的本质到底是什么呢?是构造一个分类准确,漂亮并且复杂的分类体系吗?当然不是!编程的最终目的就是完成一个任务,这个任务需要多个对象配合,换句话说就是各个对象能够彼此发送消息(A对象给B对象发消息就是A对象调用B对象的某个方法。)现代面向对象编程的本质就是轻对象分类体系(少用继承),而重视可替代关系的表达和实现。有了这种可替代关系的加持,对象之间就能更好的彼此合作(对象间调用彼此方法),从而更好地完成一个任务。
一旦我们把is-a关系换成is-substituable(可替换关系),我们就完成了面向对象编程部分的思想改造,但是不要忘记,C++是一门静态语言,不是动态语言。就语言技术本身,我们还不能像Python语言那样直接地支持动态数据类型(鸭子类型)。 但是感谢C++的generic编程。这给现代C++语言打开了一扇新的大门,使得我们不用使用继承也能支持泛型和多态(编译期间的)。不仅如此,现代的C++语言对泛型的支持更安全,对多态的支持更高效。可以这么说,C++11以后,尤其是C++/14/17/20的不断进步和演化,为我们的现代面向对象编程提供了强大的语言技术支持,使得我们完成了现代面向对象编程部分的工具改造。
思想和工具都改造完成,我们该上码了。这里我们对一个形状求面积。 我会首先给出基于传统面向对象编程的实现,然后再给出现代面向对象编程的实现。
首先是设计一个形状的基类, 然后派生出三角形, 椭圆,圆形等等。
Class Shape{
virtual getArea() = 0;
}
Class Rectangle: public Shape{
setLength(float);
setHight(float);
virtual getArea(){return length* hight;}
}
Class Triangle: publich Shape{
....
}
float getShapeArea(Shape* ptr_shape){
return ptr_shape->getArea();
}代码相当标准和传统,这里不过多解释。请注意,使用传统的面向对象编程,你就会遇到上面我们讨论的所有的面向对象的问题。圆形是不是椭圆?点是不是个形状等等。
好吧,现在我们用现代面向对象编程的思路去解决这个问题。看下面的代码:
Template<typename T>
float getTArea(T t){
return t.getArea();
}请注意,并不是使用模板了就实现现代化了,而是这段代码背后的思想。现在我们已经不需要T一定是Shape类型了。相反地,只要在计算面积这个事情上,某个类型T有可替换性,那么它就可以上。 注意到没,我们再也不需要关注椭圆是不是圆形这个问题了。而且以后就算是出现了3D的对象,只要它在计算面积这个事情上有可替换性,那么我们的代码就不需要更改,你只需要不断的加入新类就行了。就这样。
比起Shape基类,T也是类型安全的。因为在C++编译并且实例化这个函数模板的时候,编译器会检查实例化的T类型支不支持getArea()这个函数。在C++20中,我们更是引入了concept的概念。使得对类型的静态检查变得更加简单和方便。
template <typename T>
concept supportArea = requires(T v)
{
v.getArea()
};
Template<supportArea T> //supportArea is concept
float getTArea(T t){
return t.getArea();
}不仅不再需要纠结圆形是不是椭圆这个问题了,我们还可以在可替换性上再前进一步。你想得到面积,我给你面积就得了,至于我怎么算的,你不用担心。并不是我有getArea()函数才有可替代性,而是我把面积返还给你我就有可替代性。假设有个圆形,我们想求面积,但是目前圆形中还没有实现getArea()方法,没关系,我们可以用一个矩形替换圆形来计算面积。这个理解起来很简单。我们可以把一个圆形转换成一个矩形,参考下图
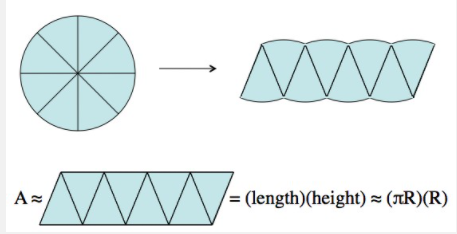
有了现代C++语言特性,实现起来也不难。参看源代码:
Template<Typename T>
float getTArea(T t){
if constexpr(Is_Circle<T>::value){
auto getArea = [](auto& t){
Rectangle r;
r.setLengh(pi*t.Radius);
r.setHigth(t.Radius);
return r.getArea();
};
return getArea();
}
else{
return t.getArea();
}
}这段代码用到了很多的C++14/17的特性,比如if constexpr,lambda和 type_trait等等。限于篇幅我不多解释了。这里简单介绍一下思想:首先构建一个Is_Circle<T> type_trait类。然后判断T是否是一个圆形,如果是,那么构建一个矩形,然后把矩形的长设置为pi*r,把高度设置为r。然后利用矩形的求面积公式计算圆形的面积。如果不是圆形,那就直接调用类型T自己的getArea。
也就是说,在求面积这件事上,只要在语义层面上满足可替换性,那么一个圆甚至可以被一个矩形所替代,而且我们也彻底摆脱了有没有getArea()函数这种语法层次的的限制。怎么样,够酷吗?
如果这个例子你读懂了,一次类似的例子还可以阅读参考文献2《Linux多线程服务端编程》。第一章里面有一个使用variadic template实现Observer设计模式的例子。书中的一个观点令我印象很深:设计复杂的分类和继承体系就是“叠床架屋”,不如直接基于对象编程(不使用继承,直接使用各种对象彼此协作),这样才能“拳拳到肉”。我深以为然。
这里必须要再提一句,可替代性的度量不仅依赖于某个函数本身的语法和语义限制,它还依赖于调用这个函数的前后条件的限制。也就是pre-condition和post-condition也要同时满足客户的要求。这么说有点抽象,再举个例子,现在有两个鸭子类,调用一个鸭子类的speak方法,它返回“quack”,调用另外一个鸭子类的speak方法,它返回“姐,好久没来了!”。单从speak方法本身,语法和语义都貌似符合可替代性。但是很明显,客户对调用speak方法后的post-codition的期待是完全不一样的。所以在这种情况下,貌似完美的可替代性是不成立的。
最后总结一下:
1)现代的面向对象设计并不是基于Is-a关系设计复杂的类继承体系。而是基于可替代关系构建一个对象间能够高效彼此协作的系统。
2) 可替代关系的理解是基于语义的,而不是基于语法的。例如有的时候语法上不可替代,但是语义上可替代就行。例如圆形即使没有getArea函数,它也可以被矩形替代(在计算面积的时候)。而有的时候,即使语法上完全可以替代,但是postcondition不满足,也不满足替代关系。例如两种不同的鸭子。
3)利用现代C++的语言特性,尤其是基于generic programming语言特性实现上面介绍的基于可替代关系的设计意图。
4)现代面向对象设计并不完全排斥对象,那种没有附加成本的基于数据抽象的对象还是推荐的。例如把一个点对象和数值对象抽象成一个圆形是推荐的。这种对象是更方便我们编程,而且没有任何附加成本。我们反对的是设计复杂的类分类和继承体系。
参考文献: